由于最近项目中要用到SpEL,于是就在51JOB学习了下相关的课程,下面是自己整理的相关的笔记,由于笔记比较散乱,希望大家包涵。
在Spel中解析表达式的过程如下:(1+2)
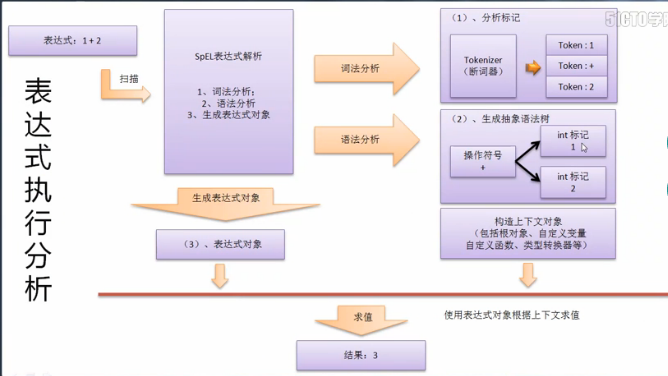
在SpEL整个的处理过程之中,要针对给定的标记进行识别,而后根据识别后的结果,进行相应内容的转化处理,随后由于表达式中有可能需要进行各种变量内容的设置,所以还需要有一个构造上下文的变量环境,所以最终才可以计算出完整的最终的所需要的结果。
所有的表达式语言都有一个范围标记${、}。
表示是否使用此模板:public Boolean isTemplate();
边界开始符号:public String getExpressionPrefix();
边界结束符号:public String getExpressionSuffix();
可以添加自定义边界:#[ ]
SpelExpressionParser() ; // 定义一个Spring表达式解析器
// 2、定义一个表达式的处理类
Expression exp = parser.parseExpression(str, new ParserContext() {
@Override
public boolean isTemplate() {
return true ;
}
@Override
public String getExpressionSuffix() {
return "]";
}
@Override
public String getExpressionPrefix() {
return "#[";
}
}) ; // 从字符串里面解析出内容
字面表达式
直接定义为最终取得的数据类型。
1E20 表示1X1020。支持多种数据类型:整型、长整型、布尔类型和null。
如果是null类型的话,则可以设置为Object类型。
求模:10%3
10 MOD 3
除法:10 DIV 2
关系表达式:
使用“==”(EQ) 、“!=”(NE)、“>”(GT)、“<”(LT)、“>=”(GE)、“<=”(LE)、3 between {1 ,5}
逻辑表达式:
与(and)、 或(OR)、非(!)NOT
三目运算符:
三目运算本身比较好处理。
10>2 ?‘Hello’ : ‘World’
空运算:
null==null ?‘Hello’ : ‘World’
“null?: false” false如果为空,就不要再写完整三目了
“true?: false” true
正则表达式:
123 matches ‘\d{3}’可以直接利用正则进行判断。
Class类型表达式:
| Class | 描述一个Class类的对象“T(String)” | class java.lang.String | |
| 静态属性 | T(Integer).MAX_VALUE | 2147483647 | |
| 静态方法 | T(Integer).parseInt(‘123’) | 123 | |
| 实例化对象 | new Java.util.Date() | 当前时间 | |
| Instanceof | ‘hello’ instanceof T(String) | true |
变量操作
主要EvaluationContext完成。
如果没有设置变量的具体内容,则为null。
String str = “#myvar”;
Context.setVarible(”myvar”,”wwwwww”);
Object num = exp.getValue(context,Object.class);
观察一个根变量。
默认的跟变量就是#root。
范例:方法引用
Method met = Integer.class.getMethod("parseInt",String.class);
String str = "#myInt('123')";
ExpressionParser parser = new SpelExpressionParser();
Expression exp = parser.parseExpression(str);
EvaluationContext context = new StandardEvaluationContext();
context.setVarible("myInt",met);
Object num = exp.getValue(context,Object.class);
System.out.println(num);
输出:123
范例:使用安全运算符
String str = "#root?.time" ; // 表示的是直接使用root根变量
ExpressionParser parser = new SpelExpressionParser() ; // 定义一个Spring表达式解析器
Expression exp = parser.parseExpression(str) ; // 从字符串里面解析出内容
// 现在直接为根变量进行内容的设置,但是最终执行表达式的时候没有使用到根变量,而是使用到了指定类的属性
EvaluationContext context = new StandardEvaluationContext() ;
Object num = exp.getValue(context,Object.class) ;
System.out.println(num);
这种方式的代码将可以更好的避免null所带来的问题。
范例:定义一个Message.java类
该MessageBean中只有一个Info变量,然后再applicationContext.xml中定义Message类。
<bean id = "msg" class = "cn.mldn.util.Message">
<property name = "info" value = "Hello World!!!">
</bean>
然后在程序中引入配置变量
ApplicationContext ctx = new ClassPathXmlApplicationContext(
"applicationContext.xml");
String str = "@msg.getInfo()"; // 表示引用配置文件中的bean的方法
ExpressionParser parser = new SpelExpressionParser(); // 定义一个Spring表达式解析器
Expression exp = parser.parseExpression(str); // 从字符串里面解析出内容
// 现在直接为根变量进行内容的设置,但是最终执行表达式的时候没有使用到根变量,而是使用到了指定类的属性
StandardEvaluationContext context = new StandardEvaluationContext();
context.setBeanResolver(new BeanFactoryResolver(ctx)); // 引用容器中的内容
Object num = exp.getValue(context, Object.class);
System.out.println(num);
解释List与数组的区别?
List是一个动态对象数组,内容可变。而数组是一个静态的集合,数组长度不可改变; List可以通过Collections创建不可改变的集合; 如果确定数组长度的情况下不建议使用List集合。
范例:索引访问集合
String str = "{10,20,30}[1]"; // 次时就是一个集合
ExpressionParser parser = new SpelExpressionParser(); // 定义一个Spring表达式解析器
Expression exp = parser.parseExpression(str); // 从字符串里面解析出内容
EvaluationContext context = new StandardEvaluationContext();
Object obj = exp.getValue(context, Object.class);
System.out.println(obj);
输出结果为:20
范例:设置可变的List集合
List<Integer> all = new ArrayList<Integer>() ;
all.add(10) ;
all.add(20) ;
String str = "#allData[10]" ; // 设置操作表达式,定义了一个变量
ExpressionParser parser = new SpelExpressionParser(); // 定义一个Spring表达式解析器
Expression exp = parser.parseExpression(str); // 从字符串里面解析出内容
EvaluationContext context = new StandardEvaluationContext();
context.setVariable("allData", all); // 设置可变集合
Object obj = exp.getValue(context, Object.class);
System.out.println(obj);
在以上的代码里面,遵循着索引不能超过集合长度的规则。也可以设置Set集合。
范例:设置Map集合
Map集合最大特点是通过key查找value数据
Map<String,String> all = new HashMap<String,String>() ;
all.put("老李", "超级大帅哥") ;
all.put("mldn", "www.mldn.cn") ;
String str = "#allData['老李']" ; // 设置操作表达式,定义了一个变量
ExpressionParser parser = new SpelExpressionParser(); // 定义一个Spring表达式解析器
Expression exp = parser.parseExpression(str); // 从字符串里面解析出内容
EvaluationContext context = new StandardEvaluationContext();
context.setVariable("allData", all); // 设置可变集合
Object obj = exp.getValue(context, Object.class);
System.out.println(obj);
范例:修改List集合内容
List<Integer> all = new ArrayList<Integer>() ;
all.add(10) ;
all.add(20) ;
String str = "#allData[1]=90" ; // 设置操作表达式,定义了一个变量
ExpressionParser parser = new SpelExpressionParser(); // 定义一个Spring表达式解析器
Expression exp = parser.parseExpression(str); // 从字符串里面解析出内容
EvaluationContext context = new StandardEvaluationContext();
context.setVariable("allData", all); // 设置可变集合
Object obj = exp.getValue(context, Object.class); // 返回的是修改后的数据
System.out.println(obj);
System.out.println(all);
修改Map集合
Map<String,String> all = new HashMap<String,String>() ;
all.put("老李", "超级大帅哥") ;
all.put("mldn", "www.mldn.cn") ;
String str = "#allData['老李']='超级无敌宇宙第一大帅哥'" ;
ExpressionParser parser = new SpelExpressionParser(); // 定义一个Spring表达式解析器
Expression exp = parser.parseExpression(str); // 从字符串里面解析出内容
EvaluationContext context = new StandardEvaluationContext();
context.setVariable("allData", all); // 设置可变集合
Object obj = exp.getValue(context, Object.class);
System.out.println(obj);
System.out.println(all);
范例:迭代修改List集合
List<Integer> all = new ArrayList<Integer>() ;
all.add(10) ;
all.add(20) ;
String str = "#allData.![1000 + #this]" ; // 设置操作表达式,定义了一个变量
ExpressionParser parser = new SpelExpressionParser(); // 定义一个Spring表达式解析器
Expression exp = parser.parseExpression(str); // 从字符串里面解析出内容
EvaluationContext context = new StandardEvaluationContext();
context.setVariable("allData", all); // 设置可变集合
Object obj = exp.getValue(context, Object.class); // 返回的是修改后的数据
System.out.println(obj);
System.out.println(all);
也可实现对数据的迭代修改。
Map<String,String> all = new HashMap<String,String>() ;
all.put("老李", "超级大帅哥") ;
all.put("mldn", "www.mldn.cn") ;
String str = "#allData.![#this.key + \" : \" + #this.value]" ;
ExpressionParser parser = new SpelExpressionParser(); // 定义一个Spring表达式解析器
Expression exp = parser.parseExpression(str); // 从字符串里面解析出内容
EvaluationContext context = new StandardEvaluationContext();
context.setVariable("allData", all); // 设置可变集合
Object obj = exp.getValue(context, Object.class);
System.out.println(obj);
System.out.println(all);
要想实现数据的过滤验证,可以使用“.?”。
范例:过滤数据,将key中包含有“mldn”的集合取出来生成新的集合
Map<String,String> all = new HashMap<String,String>() ;
all.put("老李", "超级大帅哥") ;
all.put("mldn", "www.mldn.cn") ;
String str = "#allData.?[#this.key.contains('mldn')]" ;
ExpressionParser parser = new SpelExpressionParser(); // 定义一个Spring表达式解析器
Expression exp = parser.parseExpression(str); // 从字符串里面解析出内容
EvaluationContext context = new StandardEvaluationContext();
context.setVariable("allData", all); // 设置可变集合
Object obj = exp.getValue(context, Object.class);
System.out.println(obj);
System.out.println(all);
这一点实际上和Stream接口的功能是有些相似的,只不过Stream使用了Lambda表达式和接口编程,更加简洁。
以上是整理的对Spel学习的笔记,不足之处欢迎留言指正,谢谢!